Voir nos cas clients
Allez plus loin avec nos ressources gratuites
La newsletter de Bulldozer
Êtes-vous prêt à accélérer ?


How Web Scraping Can Supercharge Your Marketing Strategy (8 Examples)
The web is a goldmine for marketers: trends, contacts, customer reviews, competitor strategies, pricing data — it's all out there. Web scraping lets you collect this data at scale, automatically and systematically. But how does it actually work? Which tools should you use? And what can you legally scrape?
In this guide, we cover the full picture: how scraping works technically, 8 concrete use cases for marketing and prospecting, and the constraints you need to navigate.

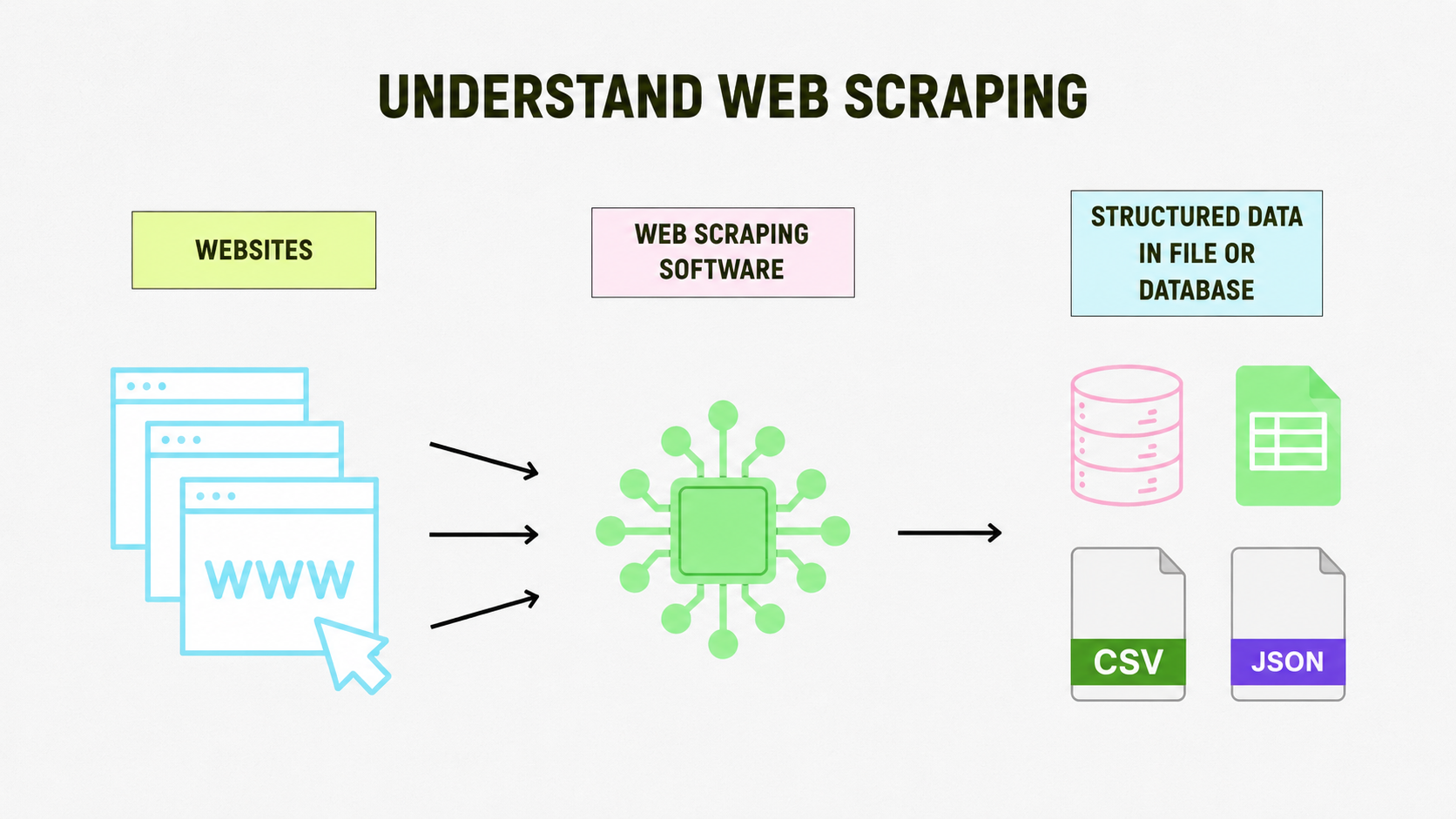
Web Scraping: What It Is and How It Works
Web scraping works like sending a virtual assistant out across the internet to grab exactly the information you need. Instead of spending hours copying and pasting content by hand, a script reads a web page and automatically pulls out the data you care about: text, images, prices, customer reviews, emails, and more.
How It Works
Websites are built with HTML code, the structure that organizes everything you see on screen. Web scraping means exploring that structure to identify and pull out specific elements: an article headline, a data table, a price list, or links to images.
Source: https://kinsta.com/fr/base-de-connaissances/web-scraping/
The Tools for the Job
Several technologies handle scraping well:
- BeautifulSoup and Scrapy (in Python) extract and organize data efficiently.
- Selenium simulates a user browsing a page and interacting with the site (clicking, scrolling, filling out a form...).
- Online services like Phantombuster or ParseHub offer ready-made, no-code solutions.
Which tool you pick depends on the type of data you're after and how well protected the target site is. Some sites block bots outright or use captchas to stop automated extraction. Handled well, though, web scraping becomes a strong way to automate data collection and sharpen your marketing strategy.
How Web Scraping Works: The Main Methods
Web scraping relies on several techniques to extract and structure data from a website. Depending on the site, its HTML structure, and the protections in place, some methods work better than others. Whether you're gathering information about a company, analyzing customer reviews, or pulling prices from a marketplace, there's a method suited to the job, built to automate extraction and get around technical roadblocks.
Here are the main approaches for scraping effectively without getting blocked.
HTML Parsing: Reading and Extracting the Right Data
Web pages are built in HTML, a structure containing every element you see on screen (headlines, text, images, links...). HTML parsing means analyzing that structure to locate and extract specific information.
- Example: automatically pulling every title and price from an e-commerce site to track competitor pricing.
- Tools: BeautifulSoup, Scrapy (Python), which let you explore the code and extract data cleanly.
Automation: Simulating a Real User
Some sites make scraping harder by requiring human interactions like clicks, scrolling, or a mandatory login. In these cases, simple HTML parsing isn't enough: you need a tool that simulates an actual user.
- Example: pulling customer reviews from a site where comments only load after you scroll down the page.
- Tools: Selenium, Playwright, which automate site navigation by opening a browser and performing actions like a human would.
Alternative APIs: When to Skip Scraping
Before scraping a site, check whether it offers an API. An API gives you official, usually more reliable access to data, with no risk of getting blocked.
- Example: instead of scraping Google Maps for a list of restaurants in a city, use the Google Places API directly.
- Tools: Google Maps API, Twitter API, OpenWeather API.
Handling Captchas and Blocks
Many sites use captchas or limit the number of requests per IP to keep bots away from their data. A few strategies get around these obstacles:
- Use proxies to rotate your IP address.
- Outsource captcha-solving to specialized services.
- Throttle your request rate to avoid getting flagged as a bot.
Example: scraping Google search results without getting blocked after a handful of requests.
Tools: 2Captcha, Anti-Captcha, Luminati (proxies).
Combine these methods and you can automate data collection efficiently and quietly. The right approach depends on the target site and the technical constraints you're working around.
Scraping for Prospecting: 4 Examples
Web scraping changes the math on prospecting. Instead of spending hours hunting down prospects one by one, it automatically surfaces valuable information about companies that are growing, local businesses, or influential creators. The result: less wasted time, more qualified contacts.
Here are four simple, effective ways to use scraping to find the right customers and boost your prospecting.
Scraping Job Listings to Spot Commercial Opportunities
Companies that are hiring are usually growing, which means new needs for software, services, or equipment. Scraping job platforms like LinkedIn, Welcome to the Jungle, and Indeed lets you identify high-potential prospects and pitch them the right solution.
- Example: a communications agency can spot startups hiring for a marketing lead and pitch its services.
- Recommended tools: Scrapy, BeautifulSoup (Python libraries built for extracting and organizing listings by specific keywords).
Scraping LinkedIn to Build B2B Prospecting Lists
LinkedIn is a goldmine for finding professional contacts and building out a B2B prospecting list. Scraping lets you collect profiles by precise criteria: job title, industry, company size. Some tools even extract professional email addresses when they're publicly available.
- Example: an HR software vendor can pull a list of HR directors in tech to offer them a free trial.
- Recommended tools: Phantombuster, TexAu (automate collecting profiles and their public data).
Scraping Google Maps to Target Local Businesses
If you're targeting local customers, Google Maps is a great source for business information: name, address, phone number, reviews, hours. Pull this data and it becomes easy to reach the right contact directly and tailor your pitch to their business and location.
- Example: a coffee supplier can pull a list of restaurants and cafés in a given city and pitch its products.
- Recommended tools: Google Maps API (the official route), Web Scraper.io (for a no-API approach).
Scraping Instagram, YouTube, and TikTok to Collect Creator Emails
Influencers play a key role in marketing strategy, but reaching out to them one by one wastes enormous amounts of time. Web scraping automates collecting their professional email addresses (listed in bios or descriptions), performance stats, and even links to their other channels.
- Example: a streetwear brand can pull a list of fashion influencers on Instagram and YouTube, emails included, to pitch a partnership.
- Recommended tools: Phantombuster, Heepsy (tools built specifically for gathering influencer data).


Scraping for Competitive and Strategic Intelligence: 4 Examples
Web scraping isn't just useful for prospecting. It's also a serious weapon for keeping an eye on competitors and catching trends before everyone else. Comparing prices, breaking down competitor strategy, understanding what customers actually want: with the right setup, you can automate all of it and get a real head start.
Here are four ways to use scraping to sharpen your competitive intelligence and stay a step ahead.
Price Comparison for E-Commerce
In online retail, prices shift constantly, and staying competitive can turn into a full-time headache. Web scraping lets you pull competitor pricing and adjust your strategy in real time.
- Example: a high-tech retailer can scrape competitor prices and automatically trigger adjustments when their rates drop or rise.
- Recommended tools: Scrapy, ParseHub (for extracting and structuring competitor pricing).
Tracking Competitor Posts and Trends on Social Media
Social media is a goldmine for watching competitor strategy and understanding what resonates with their audience. Automate the collection of posts and engagement (likes, shares, comments), and spotting the content that performs becomes easy.
- Example: a cosmetics brand can track competing influencers' posts on Instagram to spot which products drive the most engagement.
- Recommended tools: Nuzzel, BuzzSumo (for analyzing trends and top-performing posts).
Scraping Customer Reviews to Improve Your Offering
Customer reviews are a rich source of insight into what people love, and what they can't stand. Scrape reviews from platforms like Trustpilot, Amazon, or Google Reviews, and you can identify the strengths and weaknesses of your own products, and your competitors' too.
- Example: a furniture maker can analyze negative reviews of competitors' chairs to spot areas for improvement (sturdiness, comfort, delivery, etc.).
- Recommended tools: Scrapy, ReviewMeta (for pulling and analyzing customer comments).
Scraping Blogs and Forums to Spot Emerging Trends
Specialized blogs and forums are often the first to discuss new trends, long before they take off on social media. Scrape these platforms and you can catch topics as they emerge and adjust your strategy accordingly.
- Example: a sneaker brand can track discussions on forums like Reddit or specialized blogs to spot which models and collaborations are generating the most buzz before launch.
- Recommended tools: Webz.io, ParseHub (for extracting and analyzing online discussions).
Constraints, Challenges, and Limitations of Web Scraping
Web scraping is highly effective, but it isn't a free-for-all. Between the rules you need to follow, the protections sites put up, and the technical headaches involved, it pays to know where the limits are before you run into trouble. Here are the main obstacles to keep in mind.
Regulatory Compliance: What Is (and Isn't) Allowed
Just because information sits online doesn't mean you're free to collect it. In Europe, GDPR governs anything touching personal data, and in the US, laws like the DMCA protect online content. Some sites ban scraping outright in their terms of use, and ignoring that can bring real penalties.
Good practice: always check whether data can legally be used, and avoid scraping sensitive information like personal emails without authorization.
Permissions and Restrictions: robots.txt and Request Limits
Many sites set their own rules through a robots.txt file, which spells out what can (and can't) be scraped. Others enforce request limits to keep their servers from getting overwhelmed by overly aggressive bots.
Good practice: always check the robots.txt before scraping a site, and space out your requests so you don't get blocked too quickly.
Technical Challenges: What Makes Scraping Hard
Even when a site doesn't block bots outright, plenty of things can complicate data collection:
- The site keeps changing: if its HTML changes, your scraping script can stop working overnight.
- Captchas and anti-bot protections: more and more sites detect bots and block automated requests.
- Messy data: what you pull isn't always clean. You often need to clean and organize the information before you can use it.
- Too much data at once: scraping large volumes of information is great, but you need somewhere to store it and a plan for processing it.
How to handle it: use proxies to avoid getting flagged, track site updates, and organize your data properly with a SQL database or a cloud solution.
Server Impact: Don't Overload Requests
Scraping a site too aggressively can get you blocked immediately, and it can also slow the site down for other users. Some sites respond with drastic measures like IP bans or tighter security.
Good practice: don't fire off too many requests at once, and use an API when one's available. It's usually cleaner, faster, and keeps you off the radar.
Web scraping is a strong way to automate prospecting, track competitors, and catch trends fast. With these 8 concrete examples, you now have a solid picture of what it can do for your marketing.
That said, scraping carelessly causes problems. Stick to the rules, don't overload sites, and favor an API when one exists.
To get started, test tools like Phantombuster, Scrapy, or ParseHub on small projects before scaling up. Used well, scraping can genuinely accelerate your marketing strategy.
.avif)