Voir nos cas clients
Allez plus loin avec nos ressources gratuites
La newsletter de Bulldozer
Êtes-vous prêt à accélérer ?


Data Scraping: How to Collect Web Information Effectively in 2026
Data scraping, also known as web scraping, is one of the most efficient ways to collect online information at scale in 2026.
Competitive intelligence, SEO, pricing, lead generation — when used correctly, it becomes a genuine engine for supercharging your marketing and data strategies.
In this article, we explain how scraping works, how to use it legally, and which tools to choose to get started.

Analyze this content with AI
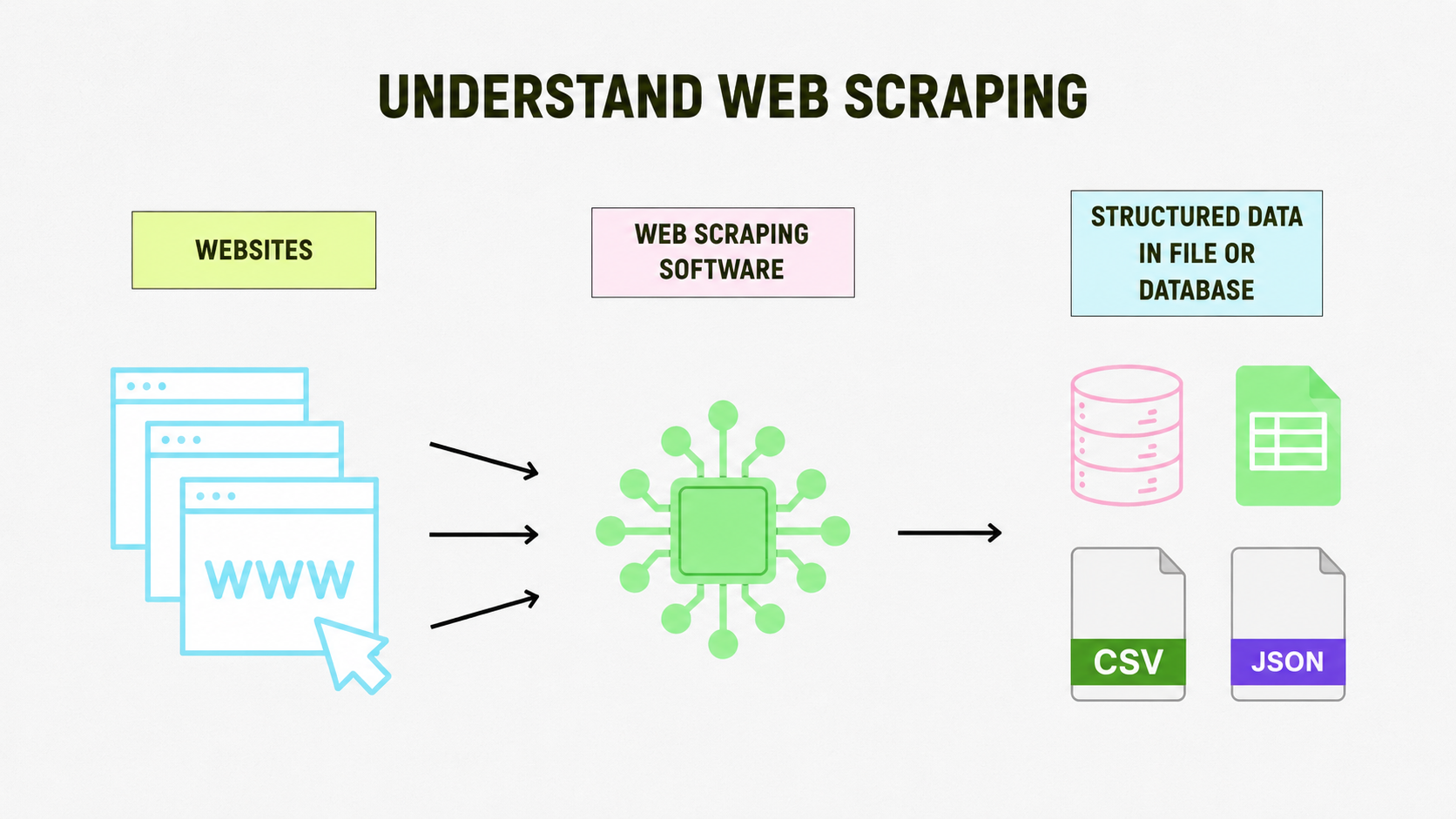
Defining data scraping: how it works, key distinctions, and what it means for marketing professionals
What is data scraping (or web scraping)?
Data scraping — also called web scraping — refers to the automated collection of publicly accessible information from a website, using scripts or specialized tools.
Rather than manually copying text or tables from a site, you program a bot to extract the data you need (prices, titles, emails, product listings…) quickly and in a structured format.
The technical version:
The scraper reads the HTML source code of a target site, identifies the elements to extract (via CSS selectors, XPath, tags) and transforms them into usable data: CSV, JSON, database, or via API.
The simple version:
It's like sending a virtual assistant to scour the internet and bring back exactly the information you need — without lifting a finger.
Scraping can be done with no-code tools (like Octoparse or ParseHub) or via programming languages like Python, using dedicated libraries such as Beautiful Soup, Scrapy, or Selenium.
Scraping, Crawling, Parsing: what's the difference?
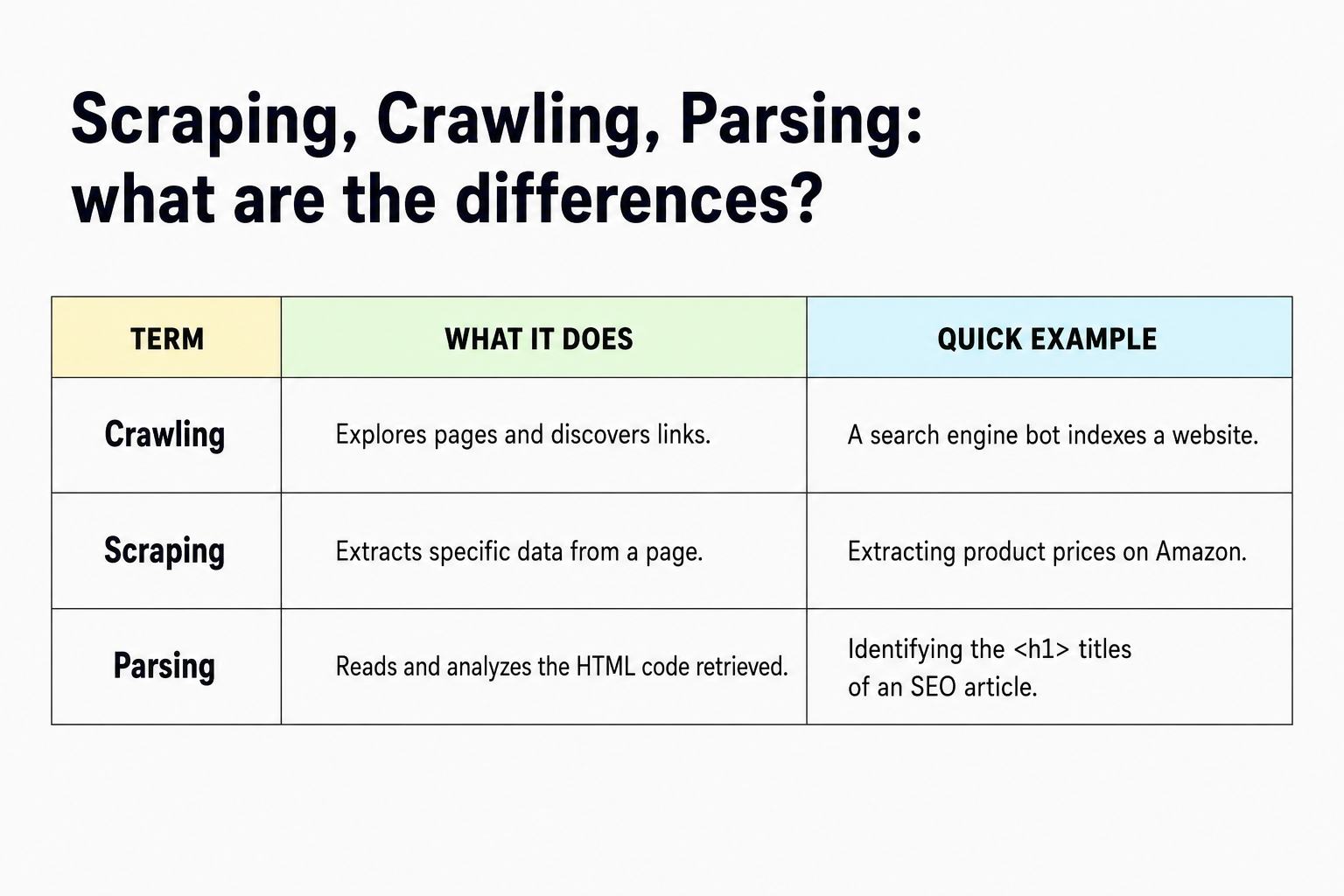
In short: crawling explores, scraping extracts, parsing sorts.
Why are more and more companies using scraping?
Data scraping addresses three core marketing needs:
- Fast competitive intelligence: monitor competitors, prices, new products, and marketing campaigns effortlessly.
- Dynamic pricing: adjust your prices in real time with clear market visibility.
- Content creation and lead generation: feed your marketing tools with fresh, targeted, activation-ready data.
- Large-scale content extraction for building sector databases or training internal AI models.
Data scraping can also be used to commercially repurpose publicly accessible information — provided you comply with applicable legal frameworks (database sui generis rights, GDPR, privacy law).
Concrete scraping applications for B2B marketing teams
B2B data scraping is far more than a time-saver: it's a strategic tool for automating competitive intelligence, boosting your SEO, optimizing prices, and accelerating lead generation.
Here's how to integrate it concretely into your marketing stack — in full compliance.
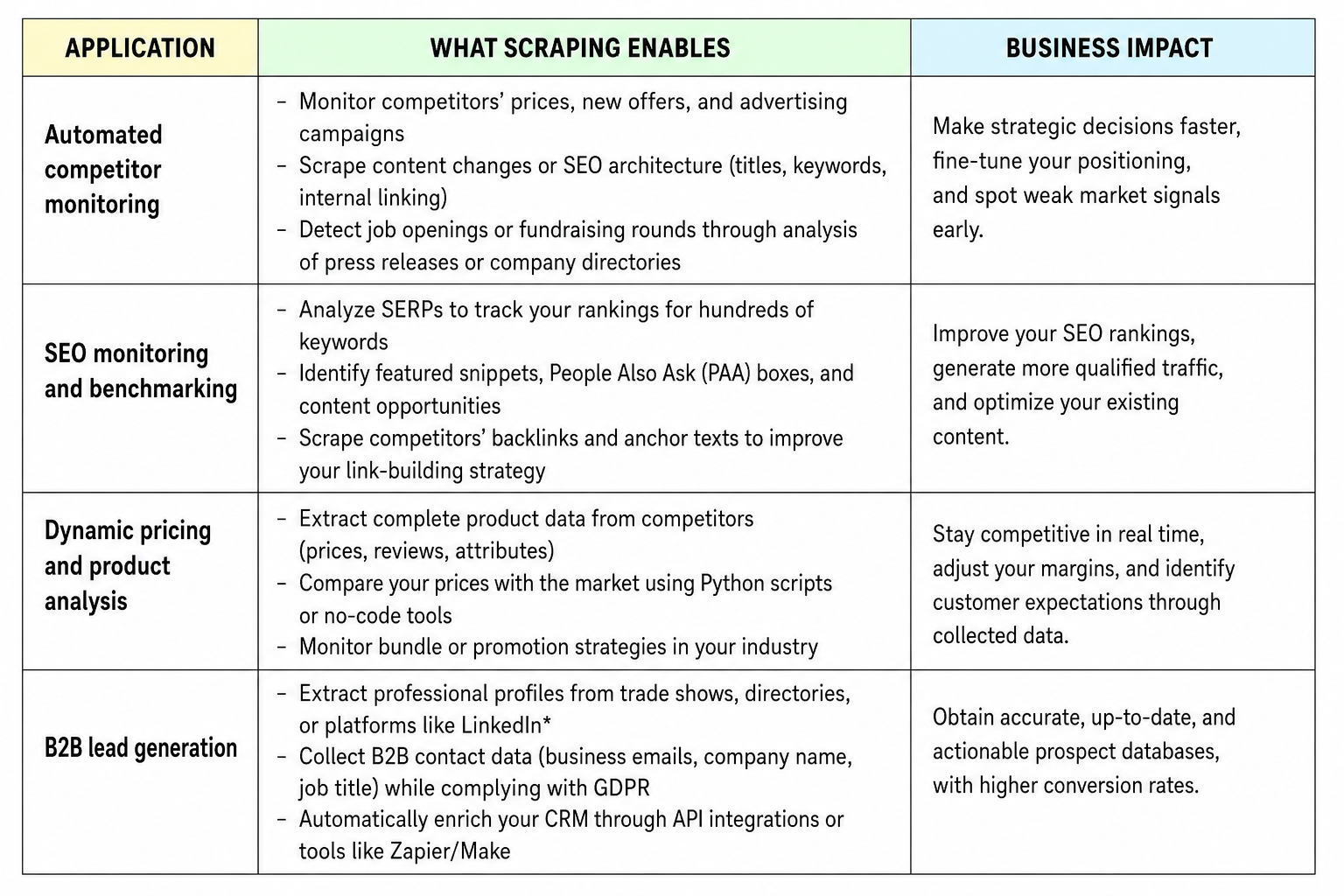
*Important: scraping personal data from a social network like LinkedIn requires strict compliance with legal frameworks (see the GDPR section). Commercially repurposing such data without explicit consent may be considered malicious scraping.
Case study: Arcane and Google Shopping
French company Arcane uses targeted, legal scraping of Google Shopping data to improve advertising performance for its clients.
Using automated product data collection (prices, stock, visibility), Arcane adjusts Google Ads bids in real time.
This makes it possible to identify when a product is well-positioned or under competitive pressure, and to reallocate budgets more intelligently.
A great example of scraping applied to a marketing use case with strong ROI, while respecting platform terms of service and data rights.
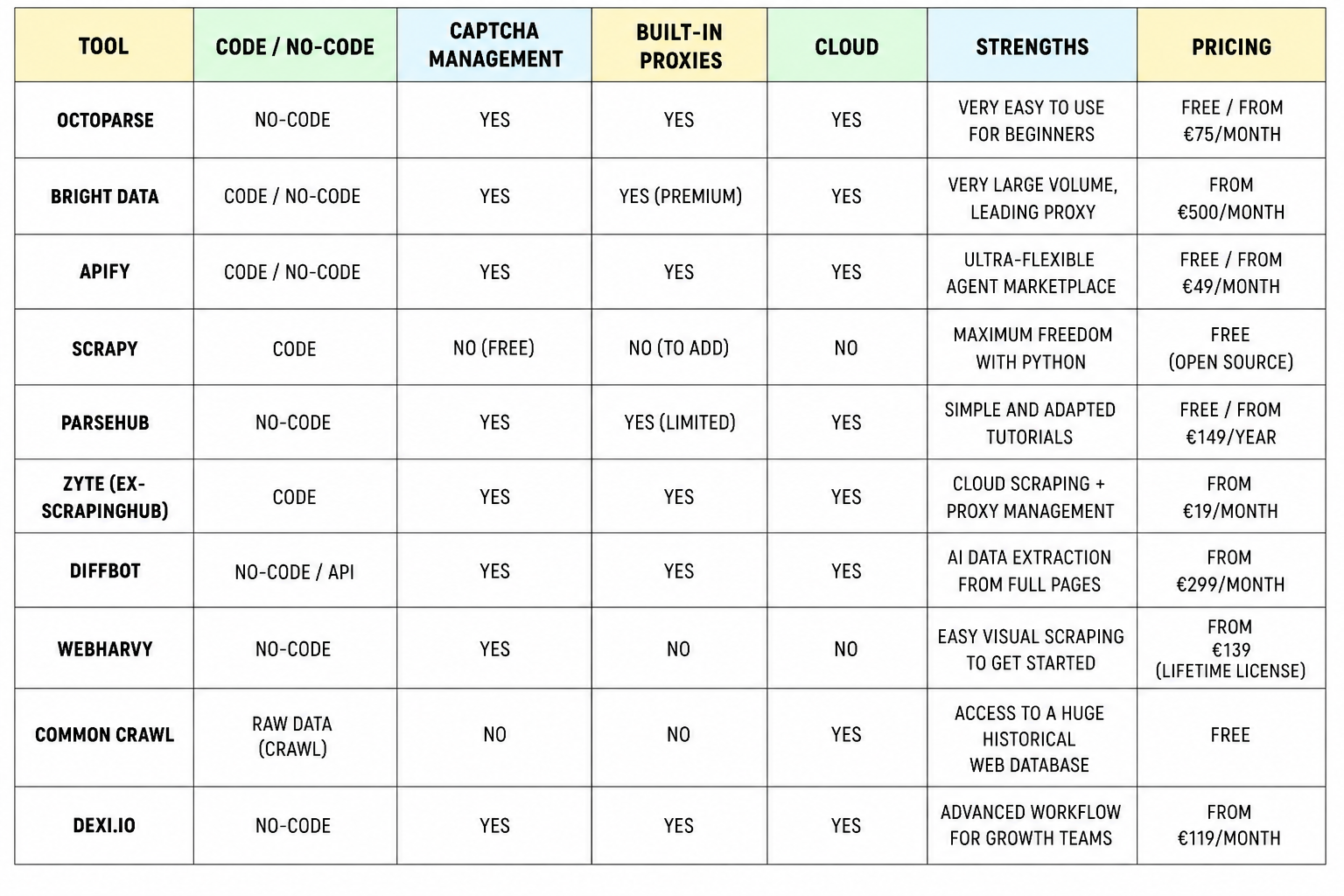
The best scraping tools in 2026: how to choose based on your needs
The web scraping tools market has diversified considerably in recent years.
Between ready-to-use no-code solutions and open-source frameworks for Python developers, there is now a very comprehensive range of options for automating web data collection — whatever your marketing objectives or technical level.
Here's how to make the right choice.
Top scraping tools comparison
No-code scraping vs. code-based scraping: which to choose?
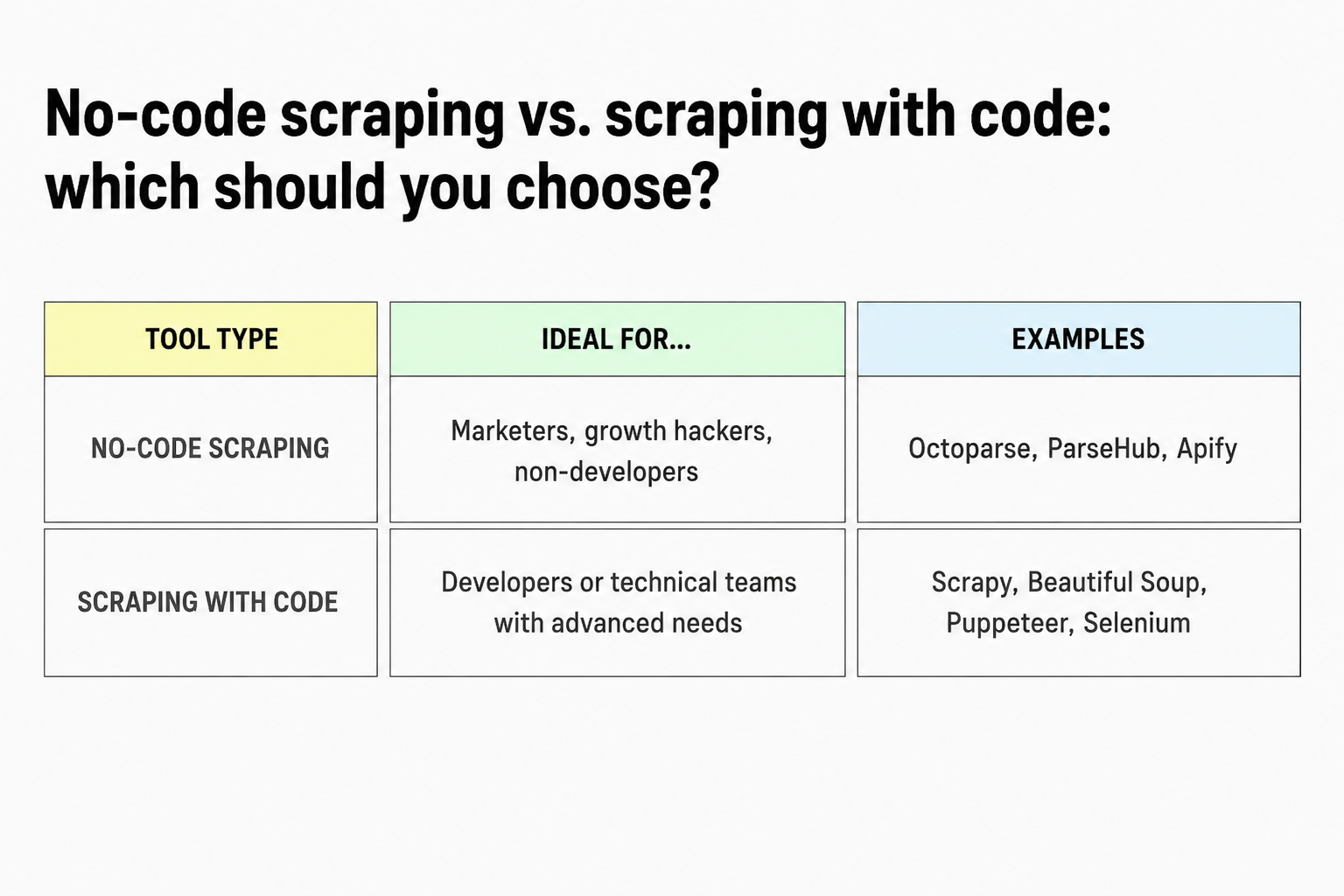
- No-code tools: no need to write a single line of code. You configure bots via a visual interface. Perfect for scraping simple sites (directories, e-commerce, articles).
- Python libraries or dedicated frameworks: access advanced features (dynamic navigation, anti-bot bypass, JavaScript content scraping).
- Ideal for complex projects or large-scale scraping.
Selection criteria for a marketing team
Before committing to a tool, here are the 4 key criteria to validate:
- CAPTCHA and anti-bot handling: Essential for bypassing security barriers (Cloudflare, reCAPTCHA, cookies, etc.).
- Integrated proxy rotation: to avoid IP blocks during large-scale automated collection.
- Cloud hosting: run agents on a schedule without keeping your computer on. Ideal for monitoring dashboards or continuous integration.
- API integrations: export to CRM, Google Sheets, Zapier, Make, or via webhook. A must for scaling your workflows.
Pricing: what to budget based on your usage
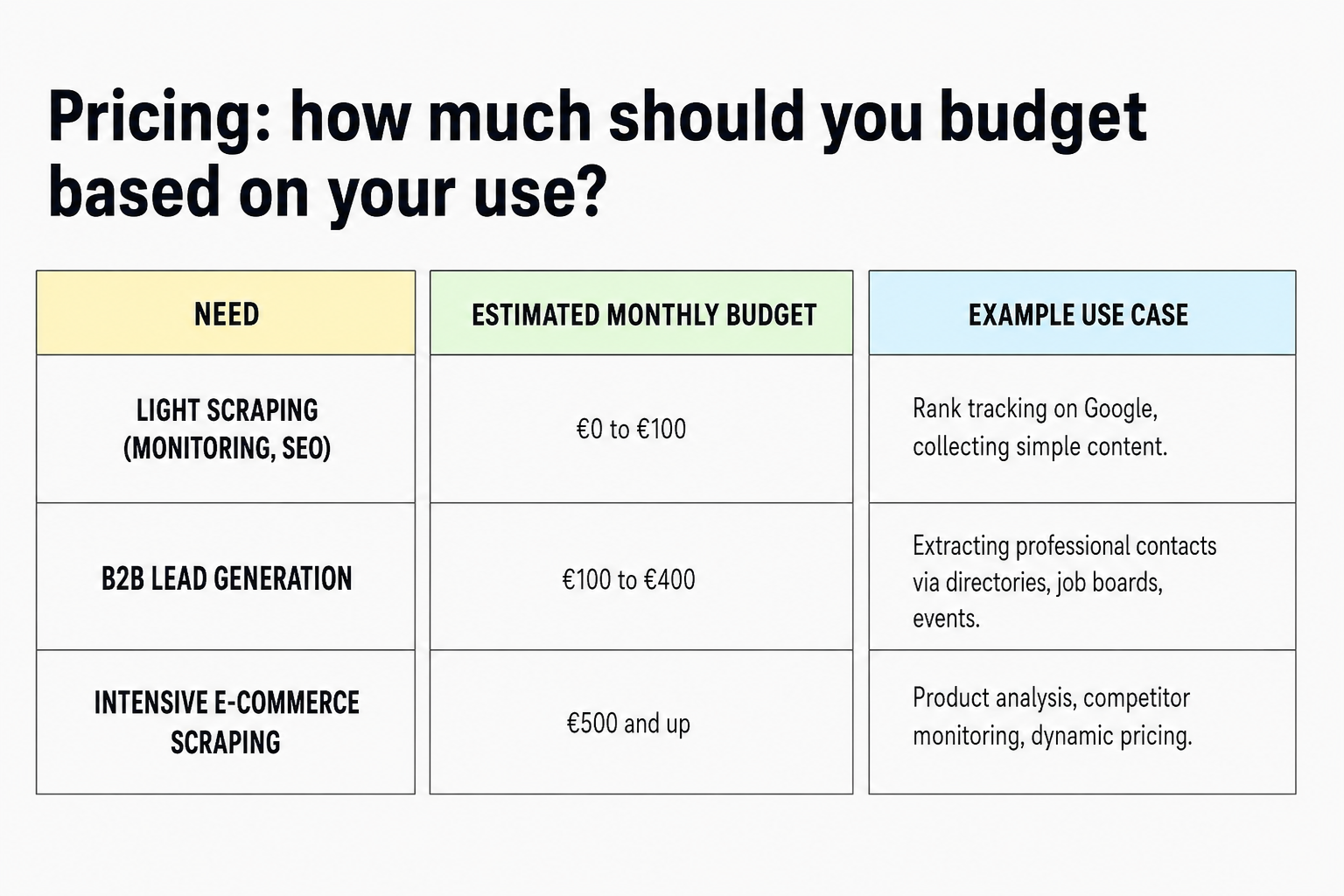
If you use an open-source framework like Scrapy or Beautiful Soup, the tools are free but require technical skills and additional services (proxy, hosting, automation).
Data scraping and GDPR: what the law says in 2026 (and how to stay compliant)
When the topic of data scraping comes up, one question always follows: "Is it legal to automatically collect data from a website?"
The answer is nuanced: scraping is legal in certain cases, but strictly regulated by European law, notably GDPR, copyright, and database sui generis rights.
The legal framework for scraping in Europe
Here are the three legal pillars to understand in order to avoid unlawful or malicious scraping:
- ✅ GDPR (General Data Protection Regulation)
- Any automated collection of personal data (name, email, professional profile…) must comply with the principles of transparency, clear purpose, and the right to object.
- This applies even if the data is publicly visible.
- ⚠️ Website Terms of Service
- Many sites explicitly prohibit scraping in their terms and conditions. Ignoring them can lead to legal action, even without any hacking involved.
- Copyright and database sui generis rights
- You cannot reproduce or reuse a structured database without authorization, especially for commercial purposes.
Special case: is scraping LinkedIn legal?
Scraping LinkedIn has become a legal grey area.
- ❌ LinkedIn explicitly prohibits scraping in its terms of service.
- ⚖️ The CNIL (French data protection authority) considers that retrieving public data for commercial purposes without consent may be illegal (source: CNIL - Scraping GDPR).
- 🇺🇸 US courts (HiQ Labs vs LinkedIn) recently ruled that scraping purely public data without hacking was not necessarily illegal. But this ruling cannot be directly applied in France or Europe.
In summary: in B2B, scraping LinkedIn at scale without authorization is risky. It's better to use legal methods and obtain consent where possible.


The 3 golden rules for compliant scraping
If you want to scrape with confidence, here are the 3 non-negotiable rules:
- Only target non-sensitive public data
- (e.g., job titles, company names — but not personal emails or phone numbers without consent).
- Respect website terms of service
- (if in doubt, ask for permission or use open sources that allow reuse).
- Implement an opt-in or notification process
- (e.g., if you contact someone identified via a directory, your email must mention the data source and allow immediate opt-out).
Ethical B2B scraping example:
Imagine you scrape a business directory containing names, job titles, and company names of marketing managers.
→ Step 1: you collect only publicly visible professional data, with no personal email addresses.
→ Step 2: you contact the person with a clear message explaining the data source, the purpose, and their right to refuse.
→ Result: you have enriched your CRM without breaching GDPR — that's ethical and compliant scraping.
Building a B2B marketing scraping strategy: objectives, stack, and technical limits
Data scraping is a powerful lever for boosting your B2B marketing strategy… provided you integrate it intelligently and build in the right safeguards from the start.
1. Define your objectives: what do you want to scrape?
Before choosing a tool or setting up your first bot, ask the right question:
Why do you want to scrape?
Some concrete objectives:
- Competitive intelligence: monitor competitor prices, product launches, positioning changes, and content updates.
- SEO optimization: track your SERP positions, identify new keyword opportunities or featured snippets.
- Dynamic pricing: adjust your rates based on real-time competitive data.
- Lead generation: collect professional contact data from authorized sources (directories, trade shows, platforms) to fuel your campaigns.
2. Build an appropriate scraping stack
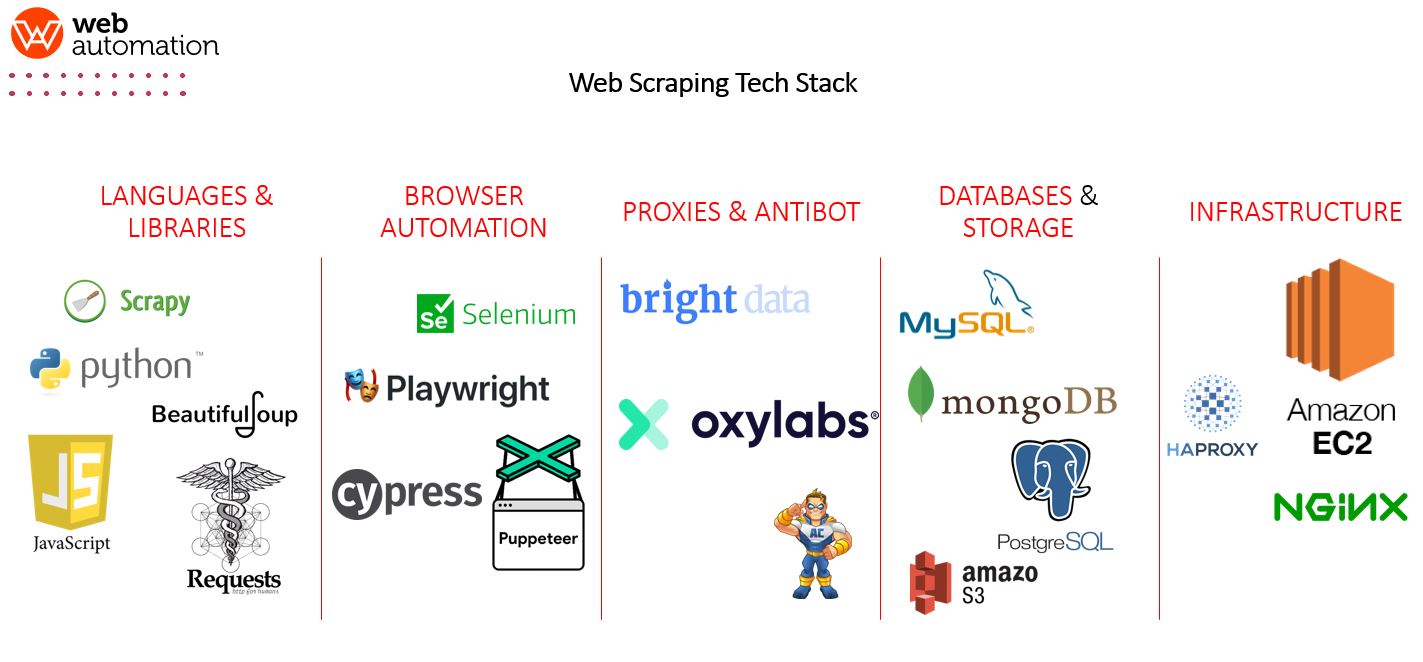
Here's how to structure your scraping ecosystem without overcomplicating things:
- Scraping tool: choose based on your profile (e.g., Octoparse for no-code, Scrapy for developers).
- Proxy and anti-bot management: to avoid blocks, especially on security-sensitive sites.
- Automation tools: Zapier, Make (ex-Integromat) or Airflow to run your scraping jobs at regular intervals.
- Data cleaning: run collected data through Google Sheets, OpenRefine, or a custom script to clean it up.
- Push to your CRM or database: to use your data directly in marketing activities.
Simple stack example for a marketing team without developers:
→ Octoparse (scraping) → Zapier (automation) → HubSpot (CRM).

Accessible stack for a non-technical team:
→ Octoparse (scraping) + Zapier (automation) + HubSpot (CRM).
3. Anticipate the technical limits of scraping
Even with the best tools, you need to anticipate the obstacles:

With a well-designed stack, a respected legal framework, and a progressive approach, web scraping becomes a powerful strategic advantage for your B2B marketing: more responsiveness, more data, and more impact — without massive additional cost.
Key takeaway:
Scraping is a powerful tool, but it requires a real methodology to avoid blocks, collection errors, and legal issues.
Done right, it can become a solid pillar of your B2B marketing strategy — with fresh, accurate, fully actionable data.
Data scraping is no longer a luxury — it's a competitive advantage. With the right tools, the right legal framework, and a clear strategy, you can transform raw information into concrete opportunities for your B2B marketing. The best time to start? Now. Test, scrape, optimize!
.avif)